在使用LLVM作为编程语言(尤其是静态语言)后端时,生成IR是一切优化、检查和进一步编译的基础。因此,熟练使用IR Builder尤为重要。
以下笔者将以几段代码为基础,简述LLVM IR Builder中的主要方法和相关类型。
准备工作 为了顺利编译和运行本文中的代码,你需要:
创建 IR Builder 在正确配置了llvm后,就可以创建和使用IR Builder了,以下是一段(很长的)模板代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> #include <cstdio> #include "llvm/ADT/APFloat.h" #include "llvm/ADT/STLExtras.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Constants.h" #include "llvm/IR/DerivedTypes.h" #include "llvm/IR/Function.h" #include "llvm/IR/IRBuilder.h" #include "llvm/IR/LLVMContext.h" #include "llvm/IR/Module.h" #include "llvm/IR/Type.h" #include "llvm/IR/Verifier.h" #include "llvm/Support/raw_os_ostream.h" static llvm::LLVMContext context;static llvm::IRBuilder<> builder(context);static std ::unique_ptr <llvm::Module> global;int main () global = std ::make_unique<llvm::Module>("<test>" , context); global->print(llvm::outs(), nullptr ); }
头文件多得吓人?没关系,这就是我们需要的所有头文件了。当然,很多情况下,把这些头文件用一个单独的头文件包含确实会让代码显得更简洁。
在上述代码中,我们定义了三个全局变量,意义分别如下:
1 2 3 4 5 6 static llvm::LLVMContext context;static llvm::IRBuilder<> builder(context);static std ::unique_ptr <llvm::Module> global;
这三件套是我们构建llvm模块的基础。在这里,“模块”只是一个预留的空指针,我们需要真正向IR Builder“声明”这个模块:
1 2 global = std ::make_unique<llvm::Module>("<test>" , context);
如果你不熟悉C++的智能指针,上述代码可以看作(其实它们并不等价):
1 global = new llvm::Module("<test>" , context);
在“声明”了模块后,<test>模块便实际存在于上下文中了,我们可以用以下代码来显示这个模块的IR Code
1 2 global->print(llvm::outs(), nullptr );
此时,编译运行,我们会获得以下输出
模块是空的,所以我们只看到了ModuleID的定义:joy:。但至少,我们已经向生成正经的IR迈出一小步了,不是吗?
创建全局变量(常量) 模块
1 2 3 4 5 6 7 8 9 10 11 12 auto intType = llvm::Type::getInt32Ty(context); auto num = llvm::ConstantInt::get( intType , llvm::APInt(32 , 233 )); auto test = new llvm::GlobalVariable( *global.get() , intType , true , llvm::GlobalVariable::ExternalLinkage , num , "test" );
添加代码后运行程序,会获得以下输出
1 2 3 ; ModuleID = '<test>' @test = constant i32 233
可以看到,模块中增加了对test常量的定义,是类型为32位整型的233值。
同样的,也可以添加字符串等特殊类型的全局变量/常量,只是步骤更为复杂。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 std ::string str = "Hello, LLVM !" ;std ::vector <llvm::Constant *> bytes;auto byteType = llvm::Type::getInt8Ty(context);auto byteArrayType = llvm::ArrayType::get(byteType, str.size());for (auto c : str) bytes.push_back( llvm::ConstantInt::get( byteType , llvm::APInt(8 , c))); auto byteArray = llvm::ConstantArray::get( byteArrayType , bytes); auto _str = new llvm::GlobalVariable(*global.get(), byteArrayType , false , llvm::GlobalVariable::ExternalLinkage , byteArray, "str" );
添加上述代码后运行程序,获得以下输出:
1 2 3 4 ; ModuleID = '<test>' @test = constant i32 233 @str = global [13 x i8] c"Hello, LLVM !"
通过llc对输出进行编译,可以获得以下汇编(amd64架构)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 phosphorus15@ubuntu:~/llvm-test$ ./llir1 | llc .text .file "<stdin>" .type test,@object # @test .section .rodata,"a",@progbits .globl test .align 4 test: .long 233 # 0xe9 .size test, 4 .type str,@object # @str .data .globl str str: .ascii "Hello, LLVM !" .size str, 13 .section ".note.GNU-stack","",@progbits
声明函数 与传统C++类似,llvm的代码段也都是包含在函数内的,声明函数是构造指令与代码逻辑的基础。同时,函数声明也用于显式地链接来自外部库的函数。(如libc中的函数)
以C系最熟悉的main函数为例,我们用以下代码进行声明:
1 2 3 4 5 6 7 8 9 auto intType = llvm::Type::getInt32Ty(context);auto bytePtrType = llvm::Type::getInt8PtrTy(context);auto byteArrPtrType = byteType->getPointerTo();global->getOrInsertFunction("main" , intType , intType, byteArrPtrType);
添加并运行以上代码,获得输出
1 2 3 4 ; ModuleID = '<test>' source_filename = "<test>" declare i32 @main(i32, i8**)
我们也可以选择以构造函数对象的方式来给模块声明函数
1 2 3 4 5 6 7 8 9 10 11 std ::vector <llvm::Type *> printfArgs;printfArgs.push_back(byteArrType); auto printfType = llvm::FunctionType::get( intType , printfArgs , true ); llvm::Function::Create(printfType , llvm::Function::ExternalWeakLinkage , "printf" , global.get());
添加并运行以上代码,获得向应输出
1 2 3 4 5 6 ; ModuleID = '<test>' source_filename = "<test>" declare i32 @main(i32, i8**) declare extern_weak i32 @printf(i8*, ...)
模块的函数声明只能有两种链接类型,extern(默认类型)和extern_weak,在printf函数的声明中,我们显式地指定了ExternalWeakLinkage,因此在输出的IR Code中有extern_weak修饰符。
基础指令集: 运算,返回与调用 LLVM 的 “值” 在进入本节前,不妨先看一看LLVM系统中各种“值”的表示方式。
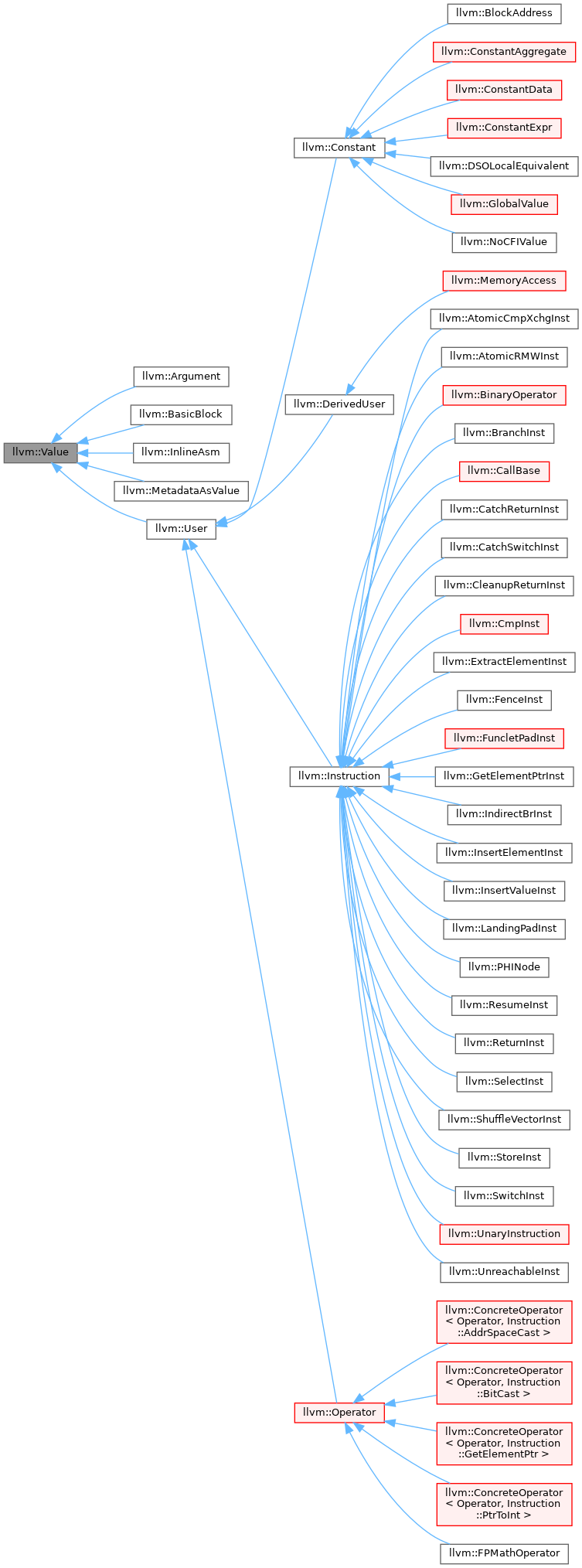
下图是一个取自官方文档的Value类继承结构图。从图中可以看出,不论是常量值,立即数值(数值常量),还是全局变量甚至指令,都继承了llvm::User,而llvm::User是llvm::Value的子类。确实,在构建IR的过程中,我们就是以llvm::Value为基指明我们IR所操作的对象的。
这种表示方式带来的好处是显而易见的——在很多熟悉的汇编指令集中,我们都需要给功能相同、但是参数类型不同(如寄存器/立即数/内存)的情形使用特定的指令。而llvm系统中值的继承方式,让我们在构建逻辑正确的前提下,避免区分不同值的“性质”而带来的烦恼。
在函数中构建指令 一段正确的的IR构建示范如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 auto functionBar = llvm::cast<llvm::Function>( global->getOrInsertFunction("bar" , intType, intType, intType, intType)); auto blockEntry = llvm::BasicBlock::Create(context, "entry" , functionBar);auto functionArgs = functionBar->args();int index = 0 ;std ::vector <llvm::Value *> argsVector;for (auto & arg : functionArgs) { arg.setName(std ::string (1 , 'a' + (index ++))); argsVector.push_back(&arg); } builder.SetInsertPoint(blockEntry); auto addtmp = builder.CreateAdd(argsVector[0 ], argsVector[1 ], "addtmp" );auto ret = builder.CreateMul(addtmp, argsVector[2 ], "retValue" );builder.CreateRet(ret); llvm::verifyFunction(*functionBar, &llvm::errs());
以上代码会获得输出:
1 2 3 4 5 6 7 8 9 ; ModuleID = '<test>' source_filename = "<test>" define i32 @bar(i32 %a, i32 %b, i32 %c) { entry: %addtmp = add i32 %a, %b %retValue = mul i32 %addtmp, %c ret i32 %retValue }
把这段IR Code交给llc生成汇编,可以看到生成的关键代码(x86架构),验证了生成的IR Code符合我们的预期:
1 2 3 4 5 6 7 8 9 10 11 bar: # @bar .cfi_startproc # %bb.0: # %entry movl 4(%esp), %eax addl 8(%esp), %eax imull 12(%esp), %eax retl .Lfunc_end0: .size bar, .Lfunc_end0-bar .cfi_endproc # -- End function
在每次函数构建完成后,利用llvm::verifyFunction验证构建的IR Code是否正确十分重要,llvm并不强制你进行验证,但及时进行验证总是一种好习惯。
在上述代码中,如果去掉builder.CreateRet(ret);一句(即不创建返回语句),在运行程序时,会看到一句来自llvm::verifyFunction的信息,警告你函数并未正确终止。
1 2 Basic Block in function 'bar' does not have terminator! label %entry
这也是llvm系统便利性的体现——在IR表示下,系统有着完整且可扩展的验证/优化/编译套件,而且大部分都是可选的模块化组件,相关支持十分完善。
今天成功把llvm开发环境从虚拟机迁移到wsl了,很开心www
构建函数调用 构建函数调用通过IR Builder中的CreateCall实现,标准的调用方式十分浅显。在上文已经定义了bar函数的基础上,以下通过一小段代码概括
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 auto functionBaz = llvm::cast<llvm::Function>( global->getOrInsertFunction("baz" , intType)); auto blockEntryBaz = llvm::BasicBlock::Create(context, "entry" , functionBaz);std ::vector <llvm::Value *> barArgs;for (int i = 0 ; i < 3 ; i++) barArgs.push_back(llvm::ConstantInt::get(intType, llvm::APInt(32 , 1 << i))); builder.SetInsertPoint(blockEntryBaz); auto calltmp = builder.CreateCall( functionBar , barArgs , "calltmp" ); builder.CreateRet(calltmp);
这里我们首先创建了一个baz函数,并在baz函数内用三个常量(立即数)调用了bar函数。生成的对应IR Code如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ; ModuleID = '<test>' source_filename = "<test>" define i32 @bar(i32 %a, i32 %b, i32 %c) { entry: %addtmp = add i32 %a, %b %retValue = mul i32 %addtmp, %c ret i32 %retValue } define i32 @baz() { entry: %calltmp = call i32 @bar(i32 1 , i32 2 , i32 4 ) ret i32 %calltmp }
本章节旨在大致介绍llvm的函数和指令的构建方式,如要了解更多类型的指令,可以自行翻阅文档,笔者(可能)也会在后文中补充记录一些基础指令。
SSA与控制流 LLVM中的SSA 读者在上面的代码中可能已经注意到,与很多编程语言的风格不同,LLVM IR中并未出现任何变量复用的情况。一个变量在被赋值之后,就再没有被二次赋值过。实际上,如果你尝试在IR Builder中对变量进行二次赋值,实际生成的IR中也会对二次赋值的变量进行重命名。这就要提到LLVM的SSA 性质:
SSA (Static single assignment form ), 是指在IR中,所有变量严格仅被赋值一次 ,且保证先声明后赋值 的行为,这种性质使得IR能够更高效地优化,也是LLVM中模块化优化过程(Pass)的保障。
控制流 - 无条件跳转 当提到一款编程语言, 控制流与分支跳转就不可避免地被提及。在llvm中,一个块所对应的标识符就是当前分支的标签。下面代码构建了一个死循环:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 auto functionBar = llvm::cast<llvm::Function>( global->getOrInsertFunction("bar" , llvm::Type::getVoidTy(context))); auto blockEntry = llvm::BasicBlock::Create(context, "entry" , functionBar);builder.SetInsertPoint(blockEntry); auto blockLoop = llvm::BasicBlock::Create(context, "loop" , functionBar);builder.CreateBr(blockLoop); builder.SetInsertPoint(blockLoop); builder.CreateBr(blockLoop); llvm::verifyFunction(*functionBar, & llvm::errs());
上面的代码可能不是很清晰,没关系,来分析一下输出的IR Code(见#号注释)
1 2 3 4 5 6 7 8 9 10 ; ModuleID = '<test>' source_filename = "<test>" define void @bar() { entry: br label %loop loop: br label %loop }
通过观察IR,我们至少可以明白以下几点:
br的作用就是进行无条件跳转每一个“块”其实就是一个包含代码的跳转标签
llvm IR中,除第一个入口块外,每一个块都必须显式地被其它块跳转到,不然会被判定为死块(即使是顺序连在一起也不行,如果删掉entry块里的跳转语句,IR验证时会报错)
控制流 - 布尔值与逻辑运算 在llvm中,布尔值有专门的类型i1表示,作为一个比特的单位,i1的值只能是0(对应假)或者1(对应真)。通过特定指令,可以完成一系列比较/逻辑运算:
1 2 3 4 5 6 7 8 9 builder.CreateFCmpOEQ(lvalue, rvalue, "cmpResult" ); builder.CreateICmpSGT(ilvalue, irvalue, "icmpResult" );
较完全的比较函数清单如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 FCMP_OEQ = 1, ///< 0 0 0 1 True if ordered and equal FCMP_OGT = 2, ///< 0 0 1 0 True if ordered and greater than FCMP_OGE = 3, ///< 0 0 1 1 True if ordered and greater than or equal FCMP_OLT = 4, ///< 0 1 0 0 True if ordered and less than FCMP_OLE = 5, ///< 0 1 0 1 True if ordered and less than or equal FCMP_ONE = 6, ///< 0 1 1 0 True if ordered and operands are unequal FCMP_ORD = 7, ///< 0 1 1 1 True if ordered (no nans) FCMP_UNO = 8, ///< 1 0 0 0 True if unordered: isnan(X) | isnan(Y) FCMP_UEQ = 9, ///< 1 0 0 1 True if unordered or equal FCMP_UGT = 10, ///< 1 0 1 0 True if unordered or greater than FCMP_UGE = 11, ///< 1 0 1 1 True if unordered, greater than, or equal FCMP_ULT = 12, ///< 1 1 0 0 True if unordered or less than FCMP_ULE = 13, ///< 1 1 0 1 True if unordered, less than, or equal FCMP_UNE = 14, ///< 1 1 1 0 True if unordered or not equal ICMP_EQ = 32, ///< equal ICMP_NE = 33, ///< not equal ICMP_UGT = 34, ///< unsigned greater than ICMP_UGE = 35, ///< unsigned greater or equal ICMP_ULT = 36, ///< unsigned less than ICMP_ULE = 37, ///< unsigned less or equal ICMP_SGT = 38, ///< signed greater than ICMP_SGE = 39, ///< signed greater or equal ICMP_SLT = 40, ///< signed less than ICMP_SLE = 41, ///< signed less or equal
逻辑运算与位运算都是通过同一套方法生成,分别是:
1 2 3 4 builder.CreateAnd(lhs, rhs, ret); builder.CreateOr(lhs, rhs, ret); builder.CreateXor(lsh, rhs, ret);
控制流 - 条件跳转 条件跳转真正引入了分支与循环